on
Fault management
The Fishworks storage appliance stands on the shoulders of giants. Many of the most exciting features – Analytics, the hybrid storage pool, and integrated fault management, for example – are built upon existing technologies in OpenSolaris (DTrace, ZFS, and FMA, respectively). The first two of these have been covered extensively elsewhere, but I’d like to discuss our integrated fault management, a central piece of our RAS (reliability/availability/serviceability) architecture.
Let’s start with a concrete example: suppose hard disk #4 is acting up in your new 7000 series server. Rather than returning user data, it’s giving back garbage. ZFS checksums the garbage, immediately detects the corruption, reconstructs the correct data from the redundant disks, and writes the correct block back to disk #4. This is great, but if the disk is really going south, such failures will keep happening, and the system will generate a fault and take the disk out of service.
Faults represent active problems on the system, usually hardware failures. OpenSolaris users are familiar with observing and managing faults through fmadm(1M). The appliance integrates fault management in several ways: as alerts, which allow administrators to configure automated responses to these events of interest; in the active problems screen, which provides a summary view of the current faults on the system; and through the maintenance view, which correlates faults with the actual failed hardware components. Let’s look at each of these in turn.
Alerts
Faults are part of a broader group of events we call alerts. Alerts represent events of interest to appliance administrators, ranging from hardware failures to backup job notifications. When one of these events occurs, the system posts an alert, taking whatever action has been configured for it. Most commonly, administrators configure the appliance to send mail or trigger an SNMP trap in response to certain alerts:
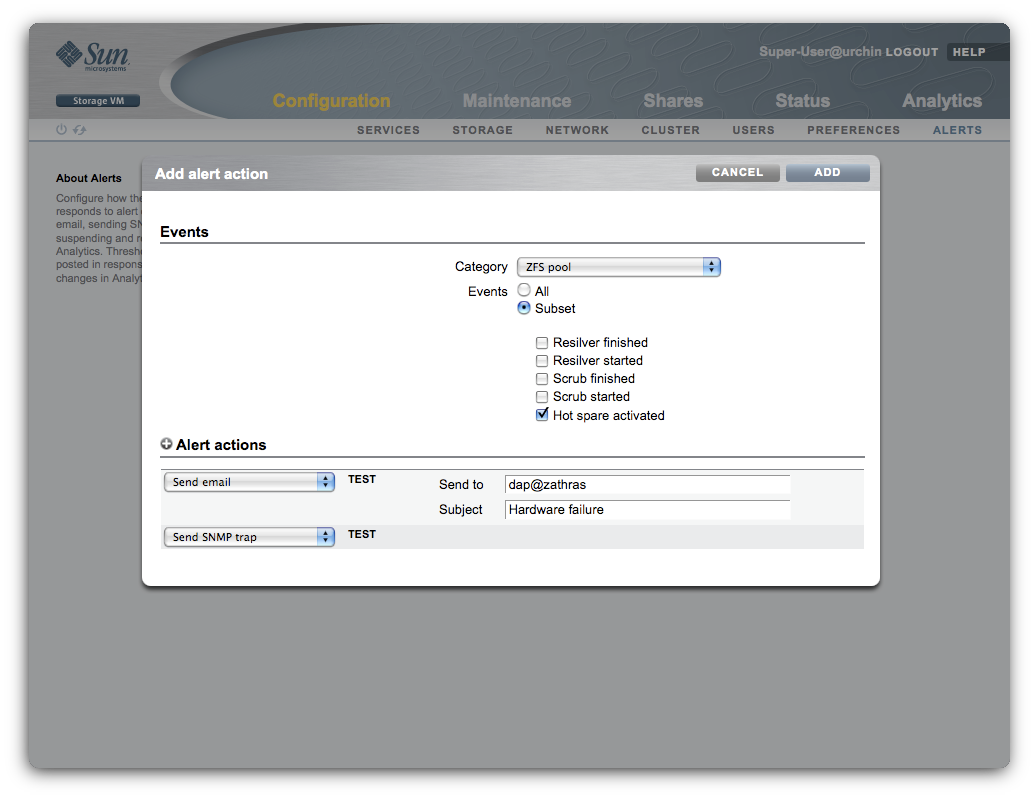
Managing faults
In our example, you’d probably discover the failed hard disk because you previously configured the appliance to send mail on hardware failure (or hot spare activation, or resilvering completion…). Once you get the mail, you’d log into the appliance web UI (BUI) and navigate to the active problems screen:
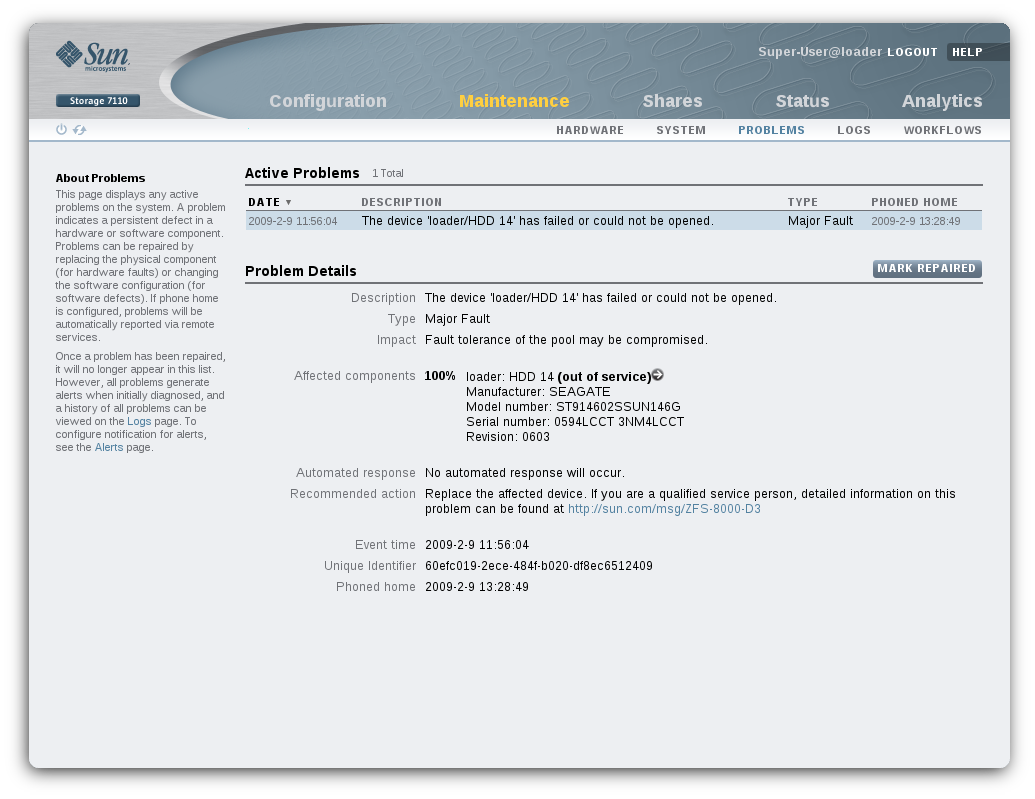
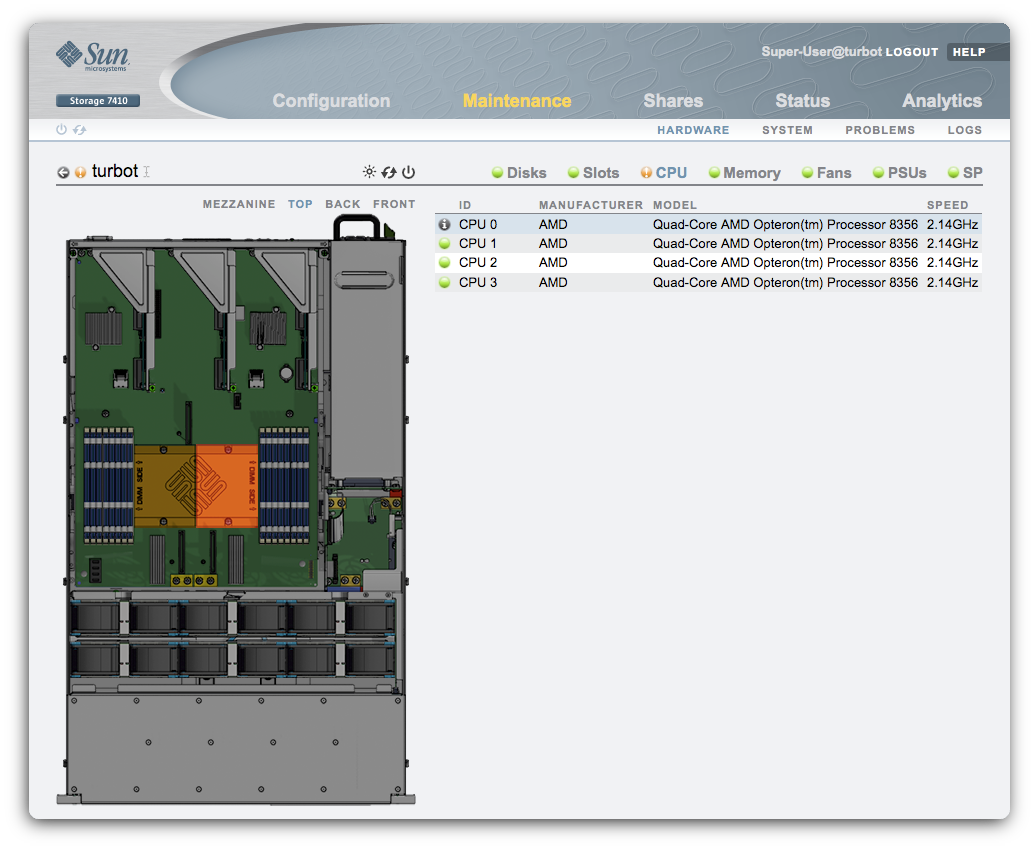
The above screen presents all current faults on the system, summarizing each failure, its impact on the system, and suggested actions for the administrator. You might next click the “more info” button (next to the “out of service” text), which would bring you to the maintenance screen for the faulted chassis, highlighting the broken disk both in the diagram and the component list:
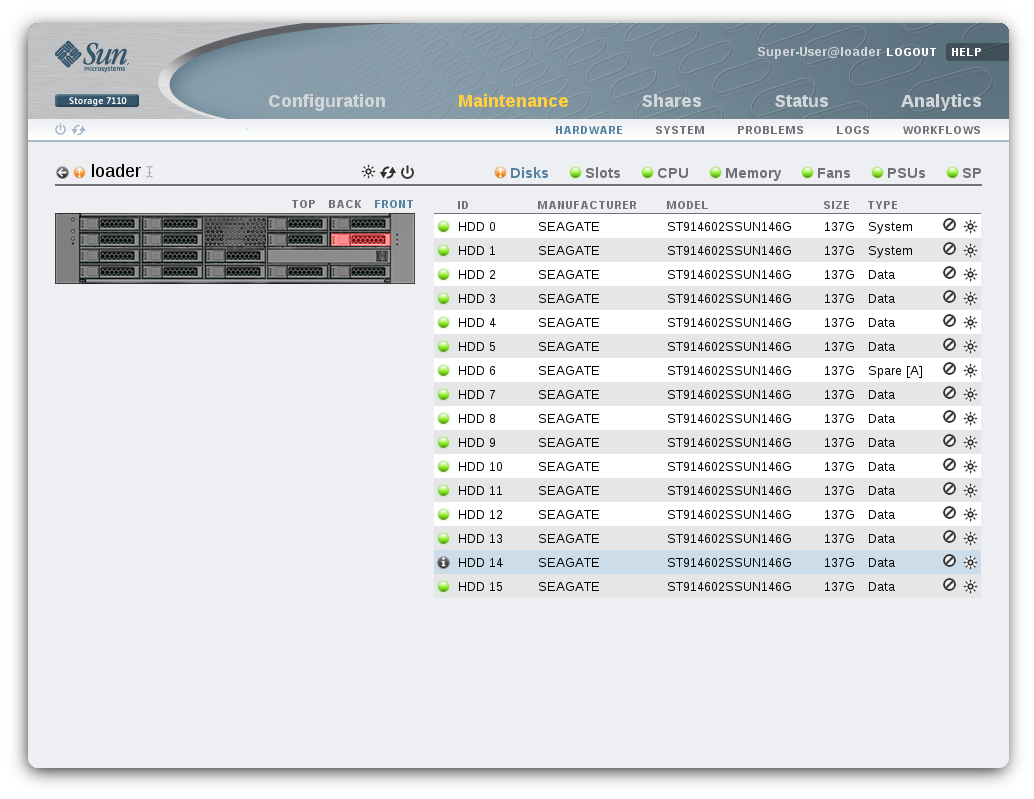
This screen connects the fault with the actual physical component that’s failed. From here you could also activate the locator LED (which is no simple task behind the scenes) and have a service technician go replace the blinking disk. Of course, once they do, you’ll get another mail saying that ZFS has finished resilvering the new disk.
Beyond disks
Disks are interesting examples because they are the heart of the storage server. Moreover, disks are often some of the first components to fail (in part because there are so many of them). But FMA allows us to diagnose many other kinds of components. For example, here are the same screens on a machine with a broken CPU cache:
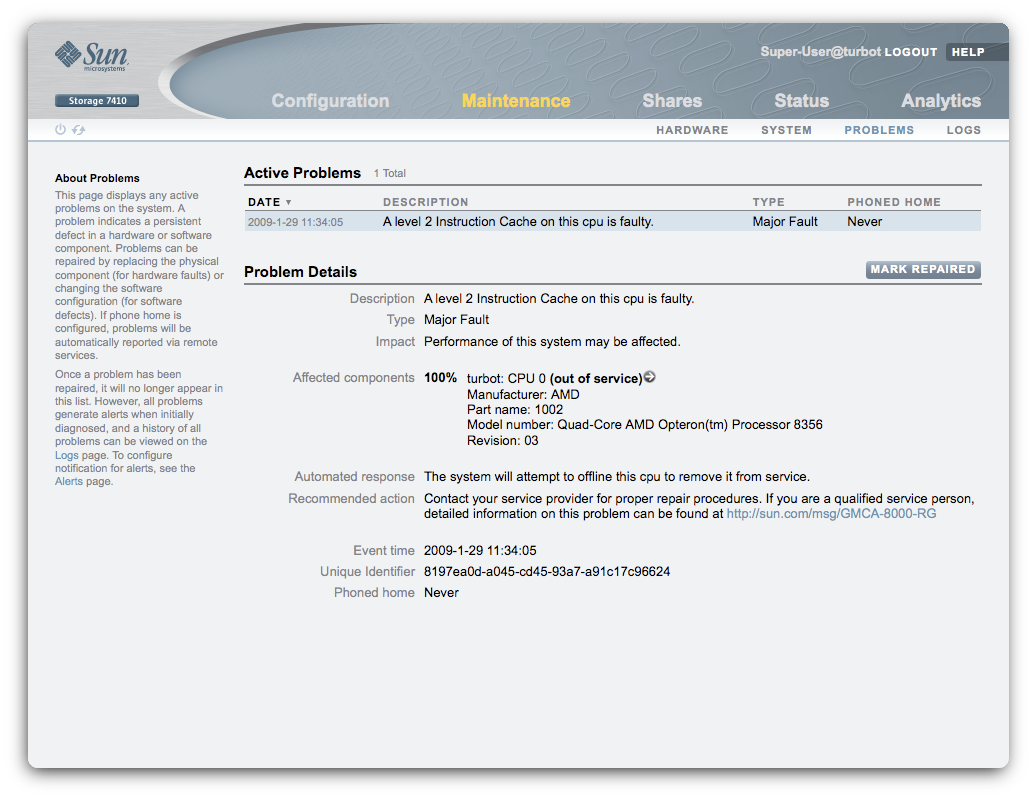
Under the hood
This complete story – from hardware failure to replaced disk, for example – is built on foundational technologies in OpenSolaris like FMA. Schrock has described much of the additional work that makes this simple but powerful user experience possible for the appliance. Best of all, little of the code is specific to our NAS appliances - we could conceivably leverage the same infrastructure to manage faults on other kinds of systems.
If you want to see more, download our VMware simulator and try it out for yourself.