on
Compression on the Sun Storage 7000
Built-in filesystem compression has been part of ZFS since day one, but is only now gaining some enterprise storage spotlight. Compression reduces the disk space needed to store data, not only increasing effective capacity but often improving performance as well (since fewer bytes means less I/O). Beyond that, having compression built into the filesystem (as opposed to using an external appliance between your storage and your clients to do compression, for example) simplifies the management of an already complicated storage architecture.
Compression in ZFS
Your mail client might use WinZIP to compress attachments before sending them, or you might unzip tarballs in order to open the documents inside. In these cases, you (or your program) must explicitly invoke a separate program to compress and uncompress the data before actually using it. This works fine in these limited cases, but isn’t a very general solution. You couldn’t easily store your entire operating system compressed on disk, for example.
With ZFS, compression is built directly into the I/O pipeline. When compression is enabled on a dataset (filesystem or LUN), data is compressed just before being sent to the spindles and decompressed as it’s read back. Since this happens in the kernel, it’s completely transparent to userland applications, which need not be modified at all. Besides the initial configuration (which we’ll see in a moment is rather trivial), users need not do anything to take advantage of the space savings offered by compression.
A simple example
Let’s take a look at how this works on the 7000 series. Like all software features, compression comes free. Enabling compression for user data is simple because it’s just a share property. After creating a new share, double-click it to modify its properties, select a compression level from the drop-down box, and apply your changes:
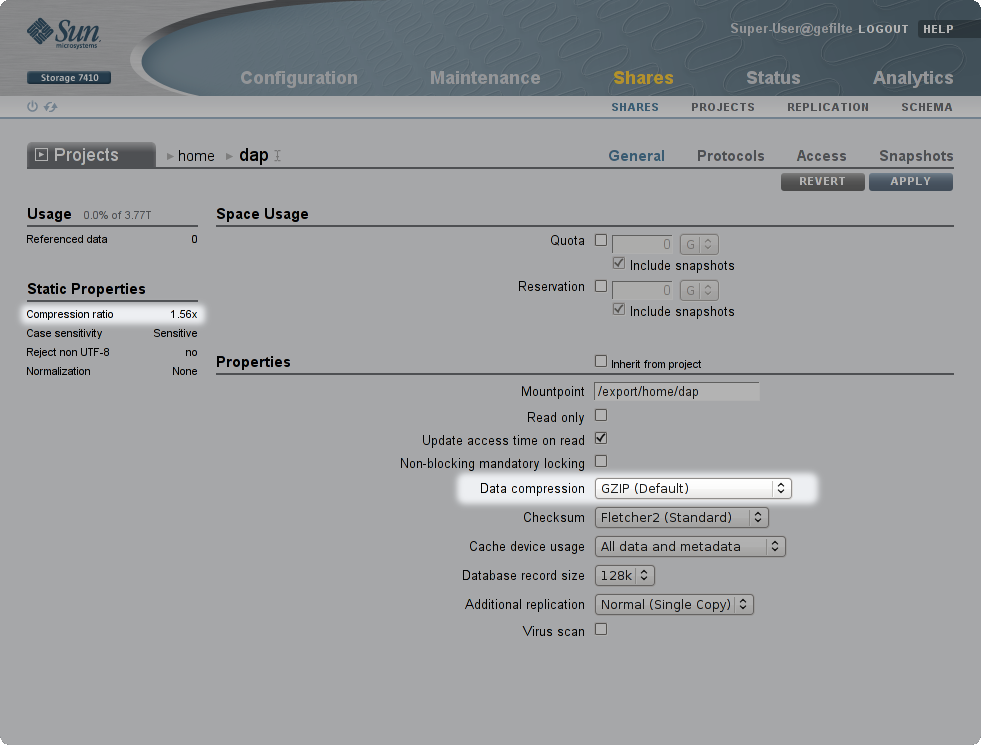
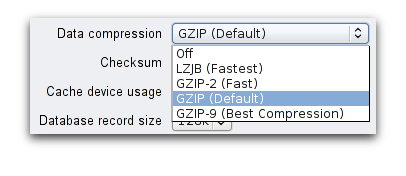 After that, all new data written to the share will be compressed with the specified algorithm. Turning compression off is just as easy: just select ‘Off’ from the same drop-down. In both cases, extant data will remain as-is - the system won’t go rewrite everything that already existed on the share.
After that, all new data written to the share will be compressed with the specified algorithm. Turning compression off is just as easy: just select ‘Off’ from the same drop-down. In both cases, extant data will remain as-is - the system won’t go rewrite everything that already existed on the share.
Note that when compression is enabled, all data written to the share is compressed, no matter where it comes from: NFS, CIFS, HTTP, and FTP clients all reap the benefits. In fact, we use compression under the hood for some of the system data (analytics data, for example), since the performance impact is negligible (as we will see below) and the space savings can be significant.
 You can observe the compression ratio for a share in the sidebar on the share properties screen. This is the ratio of uncompressed data size to actual (compressed) disk space used and tells you exactly how much space you’re saving.
You can observe the compression ratio for a share in the sidebar on the share properties screen. This is the ratio of uncompressed data size to actual (compressed) disk space used and tells you exactly how much space you’re saving.
The cost of compression
People are often concerned about the CPU overhead associated with compression, but the actual cost is difficult to calculate. On the one hand, compression does trade CPU utilization for disk space savings. And up to a point, if you’re willing to trade more CPU time, you can get more space savings. But by reducing the space used, you end up doing less disk I/O, which can improve overall performance if your workload is bandwidth-limited.
But even when reduced I/O doesn’t improve overall performance (because bandwidth isn’t the bottleneck), it’s important to keep in mind that the 7410 has a great deal of CPU horsepower (up to 4 quad-core 2GHz Opterons), making the “luxury” of compression very affordable.
The only way to really know the impact of compression on your disk utilization and system performance is to run your workload with different levels of compression and observe the results. Analytics is the perfect vehicle for this: we can observe CPU utilization and I/O bytes per second over time on shares configured with different compression algorithms.
Analytics results
I ran some experiments to show the impact of compression on performance. Before we get to the good stuff, here’s the nitty-gritty about the experiment and results:
- These results do not demonstrate maximum performance. I intended to show the effects of compression, not the maximum throughput of our box. Brendan’s already got that covered.
- The server is a quad-core 7410 with 1 JBOD (configured with mirrored storage) and 16GB of RAM. No SSD.
- The client machine is a quad-core 7410 with 128GB of DRAM.
- The basic workload consists of 10 clients, each writing 3GB to its own share and then reading it back for a total of 30GB in each direction. This fits entirely in the client’s DRAM, but it’s about twice the size of the server’s total memory. While each client has its own share, they all use the same compression level for each run, so only one level is tested at a time.
- The experiment is run for each of the compression levels supported on the 7000 series: lzjb, gzip-2, gzip (which is gzip-6), gzip-9, and none.
- The experiment uses two data sets: ’text’ (copies of /usr/dict/words, which is fairly compressible) and ‘media’ (copies of the Fishworks code swarm video, which is not very compressible). * I saw similar results with between 3 and 30 clients (with the same total write/read throughput, so they were each handling more data).
- I saw similar results whether each client had its own share or not.
Now, below is an overview of the text (compressible) data set experiments in terms of NFS ops and network throughput. This gives a good idea of what the test does. For all graphs below, five experiments are shown, each with a different compression level in increasing order of CPU usage and space savings: off, lzjb, gzip-2, gzip, gzip-9. Within each experiment, the first half is writes and the second half reads:
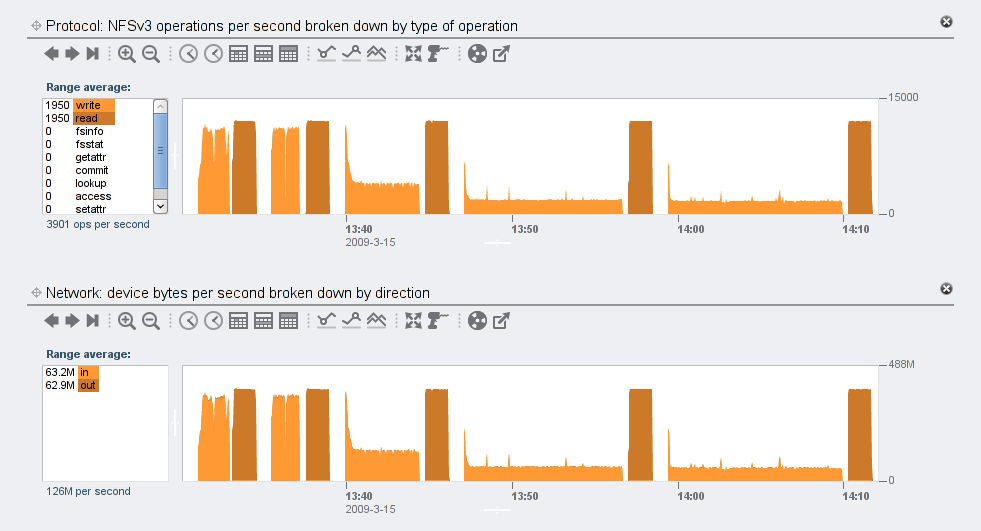
Not surprisingly, from the NFS and network levels, the experiments basically appear the same, except that the writes are spread out over a longer period for higher compression levels. The read times are pretty much unchanged across all compression levels. The total NFS and network traffic should be the same for all runs. Now let’s look at CPU utilization over these experiments:
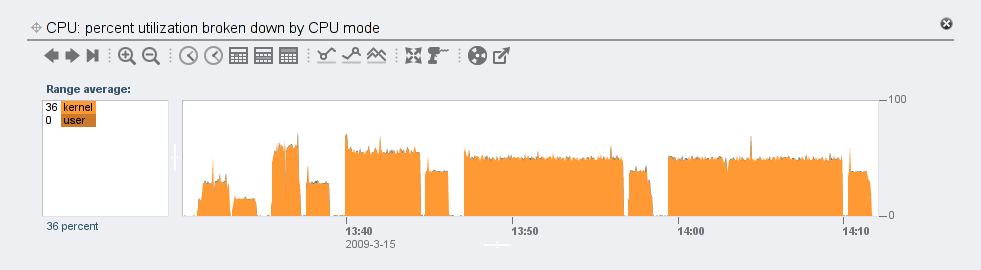
Notice that CPU usage increases with higher compression levels, but caps out at about 50%. I need to do some digging to understand why this happens on my workload, but it may have to do with the number of threads available for compres sion. Anyway, since it only uses 50% of CPU, the more expensive compression runs end up taking longer.
Let’s shift our focus now to disk I/O. Keep in mind that the disk throughput rate is twice that of the data we’re actually reading and writing because the storage is mirrored:
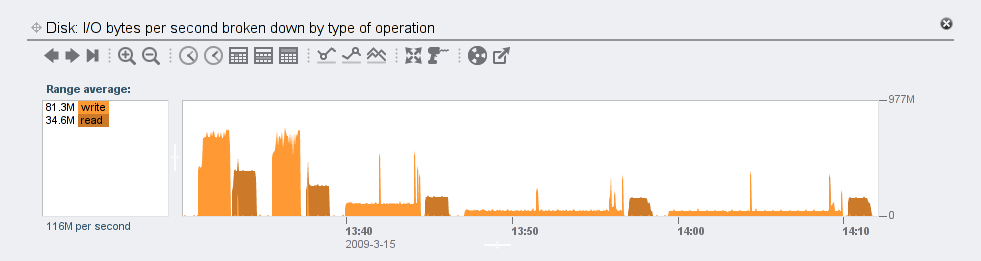
We expect to see an actual decrease in disk bytes written and read as the compression level increases because we’re writing and reading more compressed data.
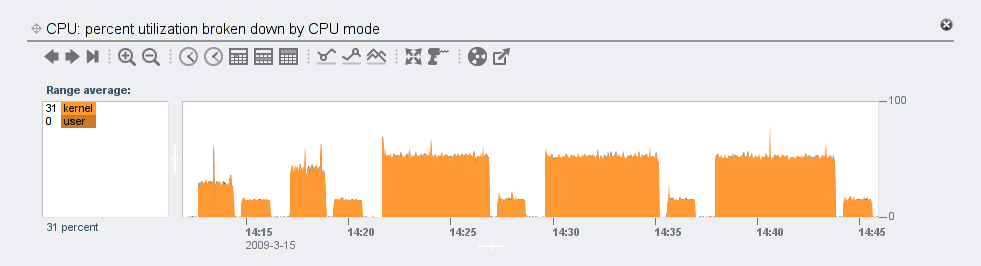
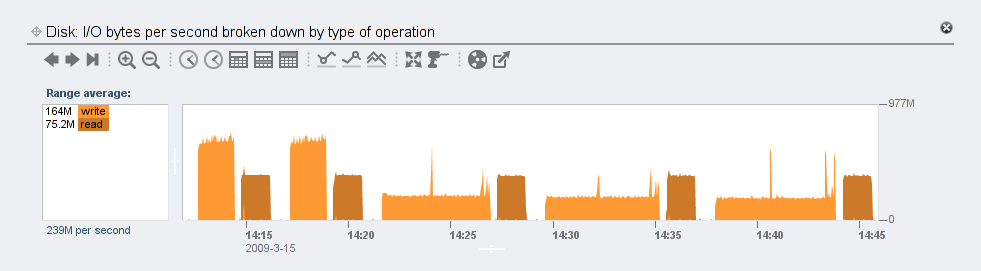
I collected similar data for the media (uncompressible) data set. The three important differences were that with higher compression levels, each workload took less time than the corresponding text one:
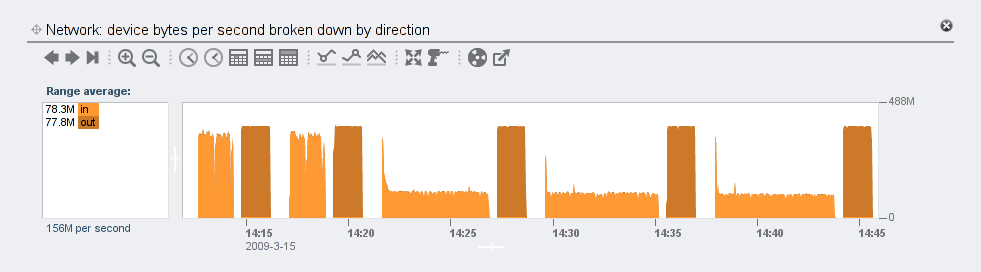
the CPU utilization during reads was less than in the text workload:
and the total disk I/O didn’t decrease nearly as much with the compression level as it did in the text workloads (which is to be expected):
The results can be summarized by looking at the total execution time for each workload at various levels of compression:
Summary: text data set
|
Summary: media data set
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
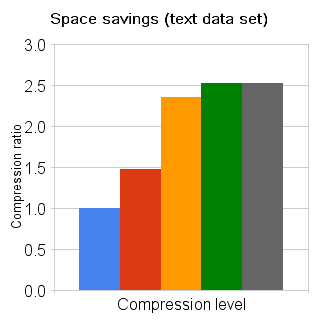 |
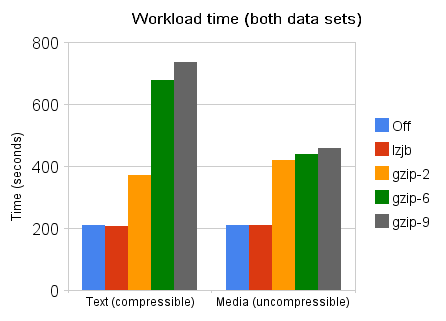 |
What conclusions can we draw from these results? Of course, what we knew, that compression performance and space savings vary greatly with the compression level and type of data. But more specifically, with my workloads:
- read performance is generally unaffected by compression
- lzjb can afford decent space savings, but performs well whether or not it’s able to generate much savings.
- Even modest gzip imposes a noticeable performance hit, whether or not it reduces I/O load.
- gzip-9 in particular can spend a lot of extra time for marginal gain.
Moreover, the 7410 has plenty of CPU headroom to spare, even with high compression.
Summing it all up
We’ve seen that compression is free, built-in, and very easy to enable on the 7000 series. The performance effects vary based on the workload and compression algorithm, but powerful CPUs allow compression to be used even on top of serious loads. Moreover, the appliance provides great visibility into overall system performance and effectiveness of compression, allowing administrators to see whether compression is helping or hurting their workload.