on
Visualizing PostgreSQL Vacuum Progress
As heavy users of PostgreSQL since 2012, we’ve learned quite a bit about operating PostgreSQL at scale. Our Manta object storage system uses a large fleet of sharded, highly-available, replicated PostgreSQL clusters at the heart of the metadata tier. When an end user requests their object, say http://us-east.manta.joyent.com/dap/public/kartlytics/videos/2012-09-06_0000-00.mov, Manta winds up looking in this PostgreSQL cluster for the metadata for that object in order to find the storage servers hosting copies of the object (along with the size, checksum, and other useful information).
From 2012 right up through the present, one of our biggest challenges has been managing PostgreSQL’s vacuum process. I won’t rehash the details here, as there’s plenty of useful information about it. Indeed, managing vacuum is such well-known challenge in operating PostgreSQL that major efforts are underway to fundamentally change the on-disk storage system to eliminate the underlying problem. Since these efforts appear years away (especially for deployments where major PostgreSQL version upgrades will take time to test and orchestrate), it remains important to understand this problem today.
This post assumes that you’re familiar enough with PostgreSQL to understand:
- The basics of a PostgreSQL database: tables, rows, indexes, and basic SQL statements.
- The terms database “page” or “block” (which I believe are used interchangeably to refer to 8KiB chunks of files making up the table’s on-disk representation), “heap” (the sequence of pages, potentially stored across several files, that store the actual table data), “tuple” (internal representation of a row), and “index” (an on-disk data structured used for efficient access to rows in the table). For more on these structures, see “Introduction to PostgreSQL physical storage”.
- Internally, row updates in PostgreSQL are processed similarly to a delete of the original row plus an insert of a new row. Since we’re not concerned about inserts in this post, we can generally just think about deletes.
- When rows are deleted in PostgreSQL tables, they are not cleaned up right away because doing so while providing desirable ACID semantics (when other transactions might still be able to see the updated or deleted rows) would make the system much more complex (and possibly slow). Deleted or updated rows (tuples) are called “dead tuples”. For more on this, see “Routine Vacuuming” from PostgreSQL documentation.
- The vacuum process is a long-running database operation that scans the heap and removes dead tuples (i.e., those invalidated by previous “update” or “delete” operations) from both the heap and indexes. Vacuum is also used to address other issues like XID wraparound, which has certainly been a major challenge for us and other providers, but it’s largely unrelated to this post.
In our production deployments, vacuum operations often take at least 5-10 days. For various reasons, it’s not uncommon for them to take 15-20 days, and we’ve seen some take upwards of 40 days. Vacuum has historically been a somewhat opaque process: it runs for a long time until it finishes, at which point it logs some basic information about what happened. Fortunately, recent versions of PostgreSQL include a view describing the progress of ongoing vacuum operations. This is fantastic! The docs are a bit light on interpreting this view, and while you can find posts explaining a bit about how to use the new view, I was left with a lot of questions. Which of the several sets of counters should we be looking at to determine overall progress? Are there even counters for all the parts we care about? Are all the counters expected to reach 100%? How do we know when certain phases will repeat and what can we do about this? This post documents how we’ve visualized the data in the view and what we’ve learned about the underlying process.
First cut: visualizing vacuum progress
We started putting together a PostgreSQL vacuum visualization by just plotting the values in the pg_stat_progress_vacuum view. We collect this information from PostgreSQL using a component we built called pgstatsmon, store it in Prometheus, and visualize it with Grafana.
First, we plot the phases:
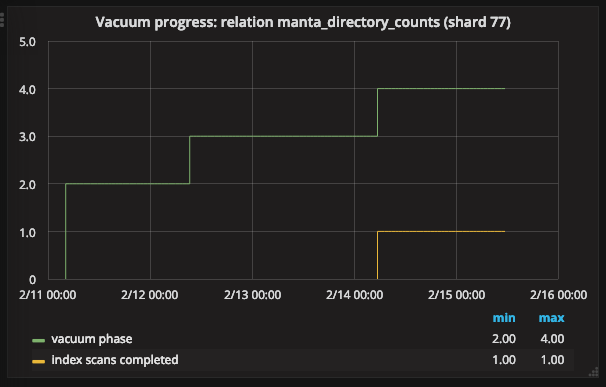
The green line shows the phases of vacuum. These are described in the docs; the key phases here are “scanning heap” (2), “vacuuming indexes” (3), and “vacuuming heap” (4). The other phases finished quickly enough that we didn’t catch them with pgstatsmon. (Note that the phase numbers here might differ from what you see because pgstatsmon adds one to the phase number reported by PostgreSQL.)
We can also add the counts of blocks scanned and vacuumed, plus the total count of blocks (which is constant):
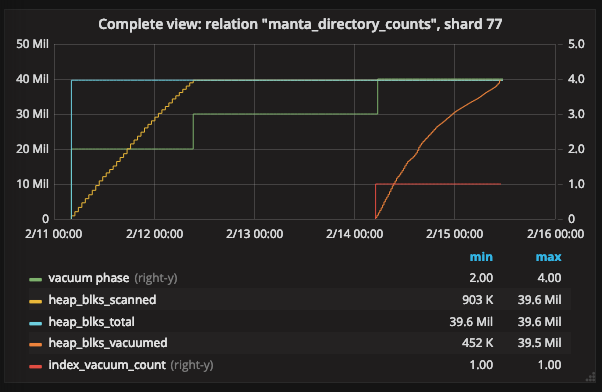
We see the count of blocks scanned (yellow line) rise up to the count of total blocks (blue line). Then we see nothing for a while, then we see the count of blocks vacuumed (orange line) rise up to total blocks (blue line again). This seems pretty useful! We have a better sense of what’s going on, where previously we just knew this was an opaque 4-day process. It’s useful to note that the lines aren’t quite linear (particularly the orange one). And there’s still a long period (about 50% of the vacuum) where we can’t see any meaningful change in progress.
The phases (the green line, now on the right y-axis) add a bit of information here: note that the count of blocks scanned increases during the “scanning heap” phase. Then we see a long, opaque “vacuuming indexes” phase. Finally, the count of blocks vacuumed increases during the “vacuuming heap” phase. (This might sound obvious, but notice that there are “scan” and “vacuum” phases for the heap and “vacuum” and “cleanup” phases for the index, so if you don’t really know what’s going on under the hood, it’s not obvious which counters increase during which phases.)
We also created a percentage view that’s a little less busy, but tells us essentially the same thing:
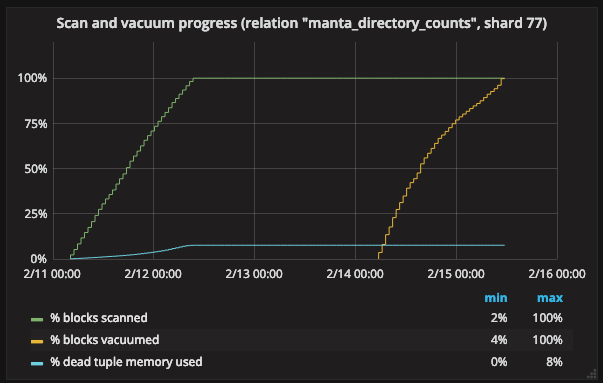
What’s going on here? Why do we seem to take two passes over the heap? What’s happening during the gap in between passes?
Diving a bit deeper: how vacuum operates
To understand PostgreSQL’s vacuum progress view, you really need to understand more about how vacuum operates. My understanding here is primarily thanks to Peter Geoghegan’s talk at PostgresOpen 2018 (slides, video). Any errors here are my own, and I’d appreciate correction from folks who know better!
First, tuples in a PostgreSQL table are identified by a ctid. This ctid is itself a two-tuple (page number, tuple number). (Pages here refer to sequential 8K pages in the heap, not operating system pages.) The page number is a type of physical address: that is, from the page number, PostgreSQL knows exactly which offset in which file contains that page. The tuple number is a logical address: it’s an ordinal number of the tuple within the page. In order to find information for that tuple, PostgreSQL looks in a sort of table-of-contents in the page’s header.
Most importantly for our discussion: this table-of-contents not only points PostgreSQL to the offset in the page where the tuple’s data is stored, but it also contains a bit indicating whether the tuple is known to be dead. If that bit is set, PostgreSQL behaves as if the tuple doesn’t exist – without even looking at the tuple data itself.
Why is all this important? Because tuples aren’t just referenced from the heap: they’re also referenced from indexes! Indexes are complex on-disk data structures that generally allow more rapid access to specific tuples – e.g., because the index is sorted by some field in the tuple. Rather than storing the entire contents of a tuple, indexes store the ctid. When a query accesses a tuple through an index, it first finds the ctid in the index, then accesses the tuple contents in the heap by ctid. (Again, if the “dead” bit is set in what I’m calling the page’s table of contents, PostgreSQL sees this when accessing the tuple before even looking at what data the tuple contains.)
In order to remove a particular tuple from the table, vacuum has to remove it not just from the heap, but also all of the indexes that reference the tuple. But there could be many indexes, and they could be huge, and they’re not necessarily structured to quickly find references to a given ctid. How can PostgreSQL find all references to a tuple – a handful of needles in a handful of haystacks – so that it can remove it from the heap without leaving references dangling from indexes?
PostgreSQL makes use of the indirection described above. Logically, the process of removing a tuple from the heap involves a few steps (note: this isn’t exactly what happens – it’s a conceptual approximation):
- Mark the tuple dead in the header of the page containing the tuple. Immediately, any attempt to reference the tuple from an index (i.e., by its ctid) will find the bit set and treat the tuple as though it’s already gone. (This is correct because vacuum has already established that this tuple really is dead. We didn’t discuss that, but vacuum can tell this because it records the id of the the oldest transaction id running when it started, and any tuple with a death transaction id older than that cannot be visible to any running transaction.)
- For each index: scan the index from start to finish for references to this ctid and remove them from the index.
- Go back to the page containing the tuple and mark the table-of-contents slot free (instead of just dead). Now this ctid can be reused for a new insert, knowing that there are no dangling references to the previous ctid.
To summarize: if PostgreSQL just reused a given ctid without first removing references from the indexes, then indexes would be left with pointers to who-knows-what in the heap. So it’s a three-step process for each tuple: mark it dead in the heap so that existing references stop working gracefully, remove references from the indexes, then actually free the slot in the heap.
PostgreSQL doesn’t scan all indexes from start to finish for each tuple it cleans up. Instead, as the vacuum process scans the heap and finds dead tuples, it marks the tuple dead as described above and adds it to a list of dead tuples it found. This list is buffered in memory, often called maintenance_work_mem after the tunable that controls how large this list can be. Later, the vacuum process scans each index from start to finish and removes references to all the tuples in the list. Then PostgreSQL goes back to the heap and completes step 3, actually freeing each ctid. In the ideal case, all of this happens once: PostgreSQL batches up the whole list of tuples and takes care of them in one whole pass over each index.
Back to the visualization
Here’s our graph of phases and blocks scanned again:
With our understanding of ctids, we can say a bit more about what’s going on:
- During the “scanning heap” phase (phase 2, on the right-Y axis), PostgreSQL is scanning through all blocks of the heap looking for dead tuples. I infer that during this phase, PostgreSQL is marking those tuples dead in the page header and adding them to the list of tuples being removed.
- During the “vacuuming indexes” phase (phase 3), PostgreSQL is scanning all of the indexes and removing tuples from each index that are also in the list of tuples being removed (accumulated during the previous phase).
- During the “vacuuming heap” phase (phase 4), PostgreSQL is going back through all the blocks of the heap and actually freeing ctids that were removed.
Great! We’ve got a decent understanding of what’s going on during a vacuum and a visualization to observe it in real-time. There are still some gaps mentioned above, like we can’t tell progress at all during the “vacuuming indexes” phase. However, there are a few things we can do with this:
- If we’re in the “scanning heap” phase, we can at least estimate when that will finish, since progress appears roughly linear. We may also guess how long the “vacuuming heap” phase will take, since it seems to be about the same (which makes sense, since they’re doing similar work). This puts a lower bound on the total vacuum time, since we don’t know how long “vacuuming indexes” will take.
- Once we reach the “vacuuming heap” phase, we could make plausible estimates about the vacuum completion time.
Is it always so simple?
Multiple index scans
Let’s take a look at more complex case:
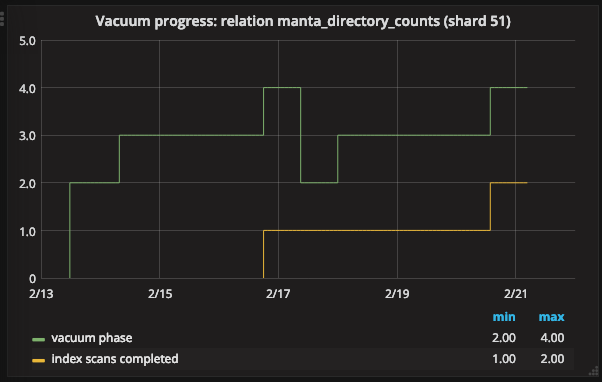
What’s going on here? It looks like the vacuum went backwards. In the table describing the vacuum phases, the text mentions that “vacuuming indexes…may happen multiple times per vacuum if maintenance_work_mem is insufficient to store the number of dead tuples found.” It also says that during the “vacuuming heap” phase, “If heap_blks_scanned is less than heap_blks_total, the system will return to scanning the heap after this phase is completed; otherwise, it will begin cleaning up indexes after this phase is completed.”
I found it a little hard to understand this from the docs alone, but the deeper information above about how vacuum works helps explain what’s going on. Above, we said that as vacuum scans through the heap, it accumulates a list of tuples that are being removed so that it can remove them from the indexes as well. That list of tuples goes into a fixed-size block of memory whose size is determined by the maintenance_work_mem tunable. What happens when we fill up this memory buffer? PostgreSQL doesn’t have a lot of options. It proceeds to finish the vacuum of the dead tuples it has already found. That means scanning (and vacuuming) all of the indexes, removing the dead tuples it’s found so far. Then it vacuums those tuples from the heap as well (just like in a normal vacuum). Now, the maintenance work memory can be cleared and it can pick up scanning the heap where it left off. Here’s what it looks like in terms of the blocks scanned and vacuumed:
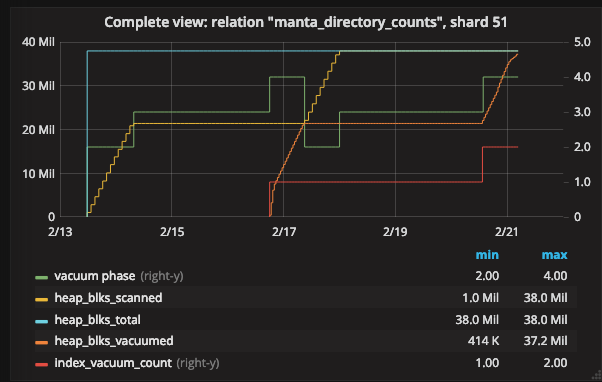
The graph is starting to get a little busy! But there’s a lot of information here.
- The green line represents the current phase. This is the same as in the graph above. The phases are indexed on the right y-axis, and the main ones are the three we saw earlier: 2 = “scanning heap”, 3 = “vacuuming indexes”, and 4 = “vacuuming heap”.
- Just like before, during the “scanning heap” phase, the count of blocks scanned increases. However, instead of increasing all the way to the total count of heap blocks, it stops at what looks like the halfway point. PostgreSQL jumps to the “vacuuming indexes” phase.
- As before, we have no progress information for the “vacuuming indexes” phase.
- Once that finishes, we move to “vacuuming heap” (again, just like the example we looked at before). Here, the count of blocks vacuumed rises up to the count of blocks scanned – and stops there.
At this point, something very interesting happens:
- PostgreSQL moves back to the “scanning heap” phase.
- The count of “index scans” increases. We didn’t talk about this before because it wasn’t that interesting. In the previous example, there was one index scan for the whole vacuum. This time, we’ve completed one index scan partway through, but the whole vacuum will require a second one.
- The heap scan picks up where it had previously stopped. (The yellow line showing blocks scanned, which had been flat for a while, starts moving up again. The orange line, which shows blocks vacuumed, now flattens.)
- This time, the heap scan makes it all the way to the end. We have another “vacuuming indexes” phase, followed by another “vacuuming heap” phase in which the count of blocks vacuumed rises to the total count of blocks.
- When the count of blocks vacuumed reaches the total count of blocks, the vacuum is essentially finished.
Essentially, the entire table vacuum has been broken up into two pieces: one covering about the first half of the heap, and another covering the rest.
We said the reason for this second scan was that PostgreSQL had filled the maintenance memory with dead tuples and had to vacuum indexes before finishing the heap scan. Can we be sure of this? Can we visualize it? Fortunately, the pg_stat_progress_vacuum view reports both the number of dead tuples accumulated as well as the total number of tuples that can be stored. We plot this against the phases:
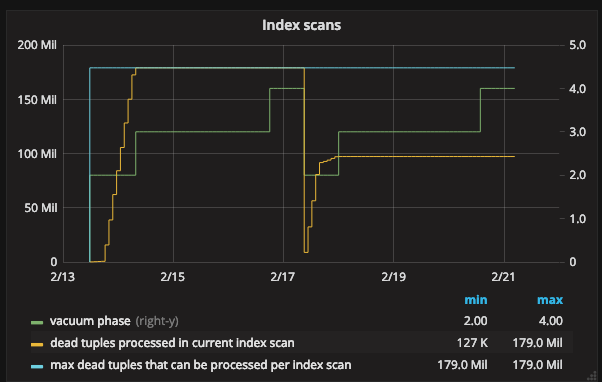
We see clearly the count of dead tuples rising up to the maximum count during the “scanning heap” phase. It remains flat for the next two phases. Having finished vacuuming those tuples, the list is emptied and PostgreSQL goes back to “scanning heap” phase. This time, we don’t quite fill up the buffer – the count of dead tuples flatlines at about half the total buffer size.
It might be clearer to look at this in terms of percentages:
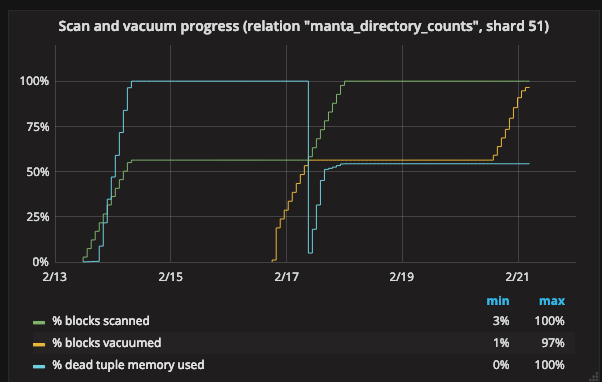
Here, we see the dead tuple memory filling up (from 0% to 100%) as we scan the heap, filling up when the scan reaches about 55%. We vacuum indexes for a while, then starting vacuuming tuples from the heap again (the yellow line increasing from 0% up to the green line, about 55%). The dead tuple memory empties (goes back to 0%), starts filling up during the scan, and flattens when we finish scanning the heap.
This visualization allows us to clearly see that the vacuum is running out of maintenance memory before finishing the heap scan and we now understand that results in an extra whole index scan.
How many index scans?
In this example, we saw two index scans. The vacuum was broken up into two pieces about halfway through the heap scan. Just to be clear, it’s only a coincidence that this happened about halfway through the scan. Here’s an example where we just barely ran out of maintenance memory (i.e., the first round made it through most of the heap before having to scan indexes):
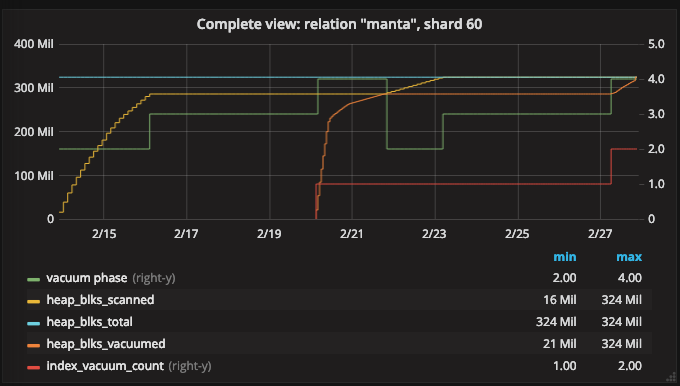
Specifically, we can see that the heap scan makes it over 80% of the way through the heap the first time. The second round is needed to finish the last bit of the heap. (Somehow, this case really emphasizes how much more expensive it turned out to be that we had to do a second index scan.)
As far as I know, it’s possible to have any number of index scans. The worst cases we’ve noticed in production involve about 5 index scans. It’s easy to tell how many have been needed for a running vacuum because it’s exposed in the pg_stat_progress_vacuum view.
Is this a big deal? All three of the vacuums that we looked at scanned the whole heap twice (once to scan, and once to vacuum each tuple) – it was just broken into two pieces for the second and third vacuums. However: these last two vacuums took two whole passes over the index files, compared to just one pass in the previous vacuum. That’s a big deal! In our case, the indexes alone are a few TiB, and in the second example, this phase took almost 3 days. Having to do a whole second scan likely added about an extra 3 days to this vacuum, nearly doubling how long it took. Yes, that’s a big deal.
Putting these graphs together, this is what our PostgreSQL vacuum dashboard looks like:
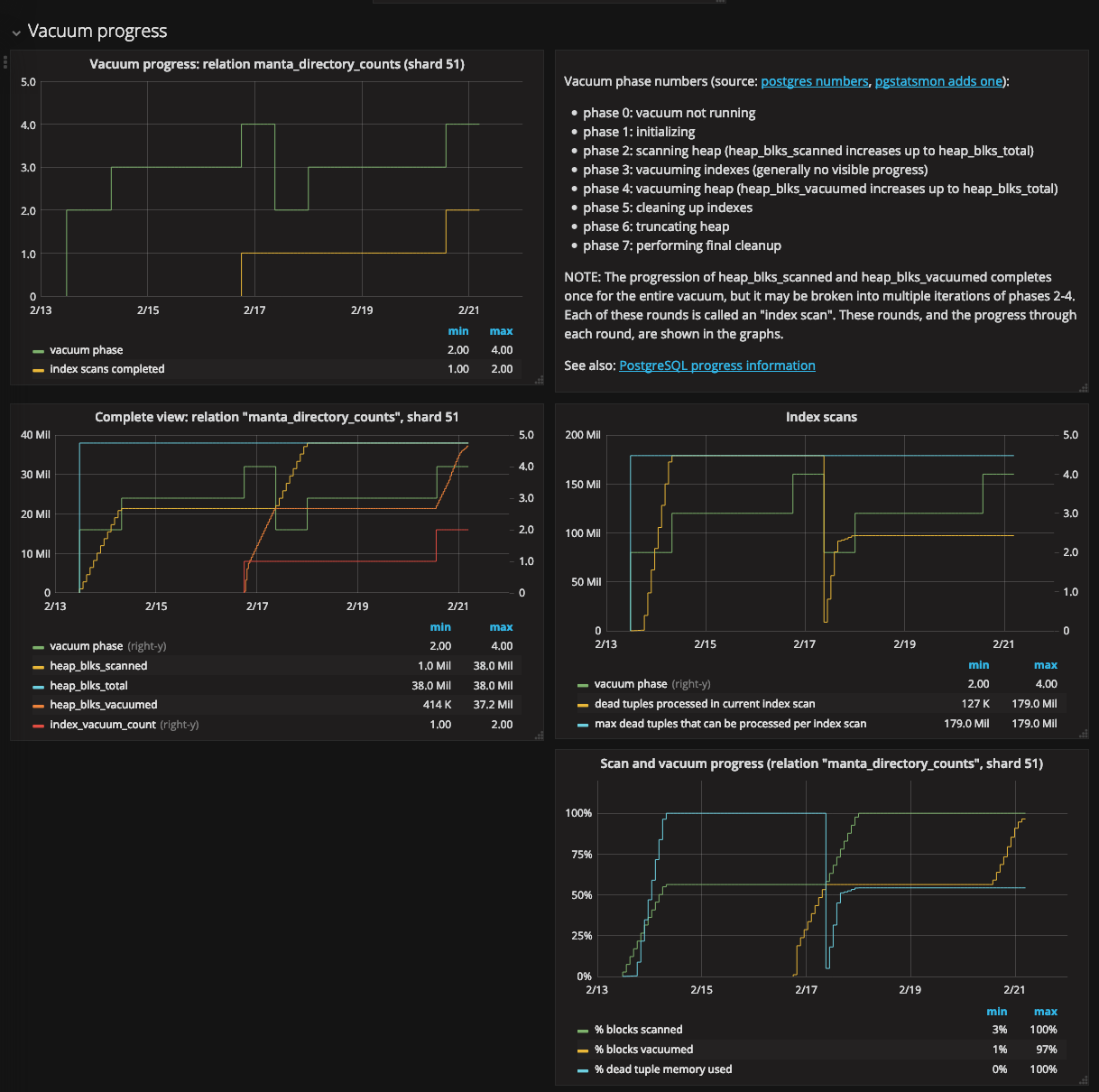
I think of this a bit like an X-Ray in that it’s quite useful in some cases but it requires pretty deep understanding to interpret. You really have to understand the multiple heap scans involved in each table scan, the index scan in between, and the use of maintenance memory and multiple index scans.
Armed with this understanding, we’ve been able to generate promising hypotheses to explain some major points of confusion. For example: we long wondered why some vacuums on the same shards take so much longer than others? Sometimes a shard will experience a 12-day vacuum, and the next one will be 20 days. We can now guess that the second vacuum required an extra index scan. If true, this is very actionable: in principle, we could tune up maintenance_work_mem. Tuning maintenance_work_mem can have an enormous impact on vacuum time, and the effect is highly non-linear. If you’ve got 520MiB worth of dead tuples, with maintenance_work_mem of 520 MiB the vacuum might take closer to 60% of the time required if maintenance_work_mem was just 512 MiB. That’s an extreme case, but the third example above isn’t far from that. (Unfortunately in our case, we’re already using a value for this larger than PostgreSQL can make use of, so there’s no low hanging fruit here.)
In terms of understanding progress:
- Once the heap scan has begun (which is essentially right away), based on progress, we can estimate how long it will take. Anecdotally, this has been comparable to the time required for the vacuum pass as well. By doubling that estimate, we get a lower bound on how long the vacuum can take. While coarse, that’s still helpful.
- If we can assume that the density of dead tuples in the heap is approximately uniform throughout the heap, we can also estimate how many index scans will be necessary for a given vacuum based on how quickly we’re filling the maintenance memory. We could even verify this assumption by seeing how quickly we fill the dead tuple memory as we scan the heap.
- Once we’ve completed a round of vacuuming indexes, we can put together a reasonable estimate of the whole vacuum’s completion time. That’s especially useful when there will be many subsequent index scans, since if there’s only one, we’re likely close to the end of the vacuum at this point anyway.
This still feels pretty rough, though. We’ve got an awful lot of open questions, starting with:
- How do we apply this to a system with several hundred shards? We can’t rely on human interpretation of a graphic.
- Is it possible to get progress information during the “vacuum indexes” phase? This is still a pretty long, opaque phase.
- Can we get information about the number of tuples frozen during the vacuum? How about the number of tuples frozen (or unfrozen) in the whole table? (This would help us understand if we should be tuning the system to freeze more aggressively during normal vacuums or if that’s causing the vacuums to take too long.)
- For each block updated, was the block updated because a tuple was frozen, some tuples were dead, or some other reason? (This would help us understand why some vacuums require more scans than others.)
Final notes
Believe it or not, this is a grossly simplified explanation of what’s going on in PostgreSQL. Peter’s talk (below) explains much more detail, including opportunistic garbage collection, heap-only tuples, the fact that most space is actually freed during the heap scan pass, and much more. Other mechanisms like hint bits, the free space map, the visibility map affect all of this.
The above represents my understanding from putting together information from the official docs, various talks, and the source. I’ve tried to cite sources where possible, but in some cases I’ve made inferences that could be way off. I’d appreciate any feedback where it’s incorrect or unclear.
The pg_stat_progress_vacuum view has been a huge step forward for us. Many thanks to the PostgreSQL community. PostgreSQL has helped us scale Manta several orders of magnitude over just a few years. The documentation is quite extensive. Thanks to those members of the community who help others understand these implementation details that play an outsize role in operating PostgreSQL at scale. And thanks especially to Peter Geoghegan for his talk at PostgresOpen in SF in 2018, which helped us put these visuals together.
It’s hard to convey how significant the vacuum issue has been for us over the last few years. To be clear, that’s in large part because of our own missteps related to database configuration, system configuration, and application behavior. (PostgreSQL defaults didn’t help either – the default behavior of vacuuming when 20% of the heap is dead means that vacuums on linearly-growing tables become farther apart and longer.) Nevertheless, some of our mistakes are quite hard to correct because they involve time-consuming, downtime-inducing schema migrations on hundreds of clusters. A lot of folks at Joyent have worked hard over the years to better understand and improve the performance of PostgreSQL at Joyent – too many to name!
Further reading:
- “Introduction to PostgreSQL physical storage” by Rachid Belaid. This post covers relevant PostgreSQL internal structures in much more detail than I did above, with more diagrams, and without assuming too much knowledge of PostgreSQL internals already.
- “Bloat in PostgreSQL: A Taxonomy”. Peter Geoghegan. PostgresOpen 2018 (slides, video). This talk inspired and informed most of this work.
- “Routine Vacuuming” from PostgreSQL documentation. This section is worth reading several times.
- “Database Page Layout” from the PostgreSQL documentation.
- “All the Dirt on Vacuum”. Jam Nasby. This link is to the latest instance of this popular talk on vacuum. You can find videos from previous versions elsewhere.
2019-07-01 Update: Grafana/Prometheus snippets
Several readers requested more details so they could more easily recreate these dashboards. Below I’ve listed out the Prometheus queries we use to draw the graphs in this post.
Our production dashboards are more complicated than I described above for reasons having nothing to do with the content of this post. We use several different Prometheus data sources, for one, and this particular dashboard is parametrized (using Grafana templates) by the PostgreSQL shard and relation that we’re looking at (among other things). With templates, Grafana shows drop-down selectors at the top of the page. These selectors fill in the $shard and $relation variables you’ll see in the queries below. These variables and their values are very specific to our deployment. If you try to use these queries, you’ll likely need to change the filters quite a bit. And remember, all of this data is collected by pgstatsmon.
The “Complete view” graph (which contains most of the interesting data) is driven by these queries:
- “vacuum phase”:
pg_stat_progress_vacuum_phase{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “heap_blks_scanned”:
pg_stat_progress_vacuum_heap_blks_scanned{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “heap_blks_total”:
pg_stat_progress_vacuum_heap_blks_total{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “heap_blks_vacuumed”:
pg_stat_progress_vacuum_heap_blks_vacuumed{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “index_vacuum_count”:
pg_stat_progress_vacuum_index_vacuum_count{relname="$relation", backend=~"$shard.postgres.*"} > 0
The “vacuum phase” and “index_vacuum_count” queries also feed the “Vacuum progress” graph. It doesn’t use any other queries.
The “Index scans” graph (which shows tuples processed) uses:
- “vacuum phase”:
pg_stat_progress_vacuum_phase{relname="$relation",backend=~"$shard.postgres.*"} > 0 - “dead tuples processed in current index scan”:
pg_stat_progress_vacuum_num_dead_tuples{relname="$relation",backend=~"$shard.postgres.*"} > 0 - “max dead tuples that can be processed per index scan”:
pg_stat_progress_vacuum_max_dead_tuples{relname="$relation",backend=~"$shard.postgres.*"} > 0
For the “Scan and vacuum progress” graph (which shows percentage progress), we use:
- “% blocks scanned”:
100 * pg_stat_progress_vacuum_heap_blks_scanned{relname="$relation", backend=~"$shard.postgres.*"}/pg_stat_progress_vacuum_heap_blks_total{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “% blocks vacuumed”:
100 * pg_stat_progress_vacuum_heap_blks_vacuumed{relname="$relation", backend=~"$shard.postgres.*"}/pg_stat_progress_vacuum_heap_blks_total{relname="$relation", backend=~"$shard.postgres.*"} > 0 - “% dead tuple memory used”:
100 * pg_stat_progress_vacuum_num_dead_tuples{relname="$relation",backend=~"$shard.postgres.*"} / pg_stat_progress_vacuum_max_dead_tuples{relname="$relation",backend=~"$shard.postgres.*"} > 0
I hope this is helpful! If there’s more information that’d be useful, let me know. (I’m not sure I can provide the raw dashboard JSON since it has details specific to our environment – but for that reason, I’m also not sure it would be very helpful.)