on
Fault tolerance in Manta
Since launching Manta last week, we’ve seen a lot of excitement. Thoughtful readers quickly got to burning questions about the system’s fault tolerance: what happens when backend Manta components go down? In this post, I’ll discuss fault tolerance in Manta in more detail. If anything seems left out, please ask: it’s either an oversight or just seemed too arcane to be interesting.
This is an engineering internals post for people interested in learning how the system is built. If you just want to understand the availability and durability of objects stored in Manta, the simpler answer is that the system is highly available (i.e., service survives system and availability zone outages) and durable (i.e., data survives multiple system and component failures).
First principles
First, Manta is strongly consistent. If you PUT an object, a subsequent GET for the same path will immediately return the object you just PUT. In terms of CAP, that means Manta sacrifices availability for consistency in the face of a complete network partition. We feel this is the right choice for an object store: while other object stores remain available in a technical sense, they can emit 404s or stale data both when partitioned and in steady-state. The client code to deal with eventual consistency is at least as complex as dealing with unavailability, except that there’s no way to distinguish client error from server inconsistency – both show up as 404 or stale data. We feel transparency about the state of the system is more valuable here. If you get a 404, that’s because the object’s not there. If the system’s partitioned and we cannot be sure of the current state, you’ll get a 503, indicating clearly that the service is not available and you should probably retry your request later. Moreover, if desired, it’s possible to build an eventually consistent caching layer on top of Manta’s semantics for increased availability.
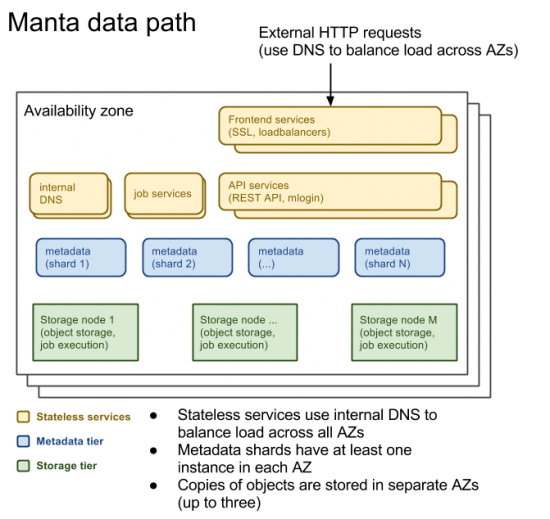
While CAP tells us that the system cannot be both available and consistent in the face of an extreme network event, that doesn’t mean the system fails in the face of minor failures. Manta is currently deployed in three availability zones in a single region (us-east), and it’s designed to survive any single inter-AZ partition or a complete AZ loss. As expected, availability zones in the region share no physical components (including power) except for being physically close to one another and connected by a high-bandwidth, low-latency interconnect.
Like most complex distributed systems, Manta is itself made up of several different internal services. The only public-facing services are the loadbalancers, which proxy directly to the API services. The API services are clients of other internal services, many of which make use of still other internal services, and so on.
Stateless services
Most of these services are easy to reason about because they’re stateless. These include the frontend loadbalancers, the API servers, authentication caches, job supervisors, and several others.
For each stateless service, we deploy multiple instances in each AZ, each instance on a different physical server. Incoming requests are distributed across the healthy instances using internal DNS with aggressive TTLs. The most common failure here is a software crash. SMF restarts the service, which picks up where it left off.
For the internal services, more significant failures (like a local network partition, power loss, or kernel panic) result in the DNS record expiring and the instance being taken out of service.
Stateful services
Statelessness just pushes the problem around: there must be some service somewhere that ultimately stores the state of the system. In Manta, that lives in two tiers:
- the storage tier, which stores the contents of users’ objects
- the metadata tier, which maps user object names to the servers where the data is stored
The storage tier
The availability and durability characteristics of an object are determined in part by its “durability level". From an API perspective, this indicates the number of independent copies of the object that you want Manta to store. You pay for each copy, and the default value is 2. Copies are always stored on separate physical servers, and the first 3 copies are stored in separate availability zones.
Durability of a single copy: Objects in the storage tier are stored on raidz2 storage pools with two hot spares. The machine has to sustain at least three concurrent disk failures before losing any data, and could survive as many as eight. The use of hot spares ensures that the system can begin resilvering data from failed disks onto healthy ones immediately, in order to reduce the likelihood of a second or third concurrent failure. Keith discusses our hardware choices in more depth on his blog.
Object durability: Because of the above, it’s very unlikely for even a single copy of an object to be lost as a result of storage node failure. If the durability level is greater than 1 (recall that it’s 2 by default), all copies would have to be lost for the object’s data to be lost.
Object availability: When making a request for an object, Manta selects one of the copies and tries to fetch the object from the corresponding storage node. If that node is unavailable, Manta tries another node that has a copy of the object, and it continues doing this until it either finds an available copy or runs out of copies to try. As a result, the object is available as long as the frontend can reach any storage node hosting a copy of the object. As described above, any storage node failure (transient or otherwise) or AZ loss would not affect object availability for objects with at least two copies, though such failures may increase latency as Manta tries to find available copies. Similarly, in the event of an AZ partition, the partitioned AZ’s loadbalancers would be removed from DNS, and the other AZs would be able to service requests for all objects with at least two copies.
Since it’s much more likely for a single storage node to be temporarily unavailable than for data to be lost, it may be more useful to think of “durability level” as “availability level”. (This property also impacts the amount of concurrency you can get for an object – see Compute Jobs below.)
Metadata tier
The metadata tier records the physical storage nodes where each object is stored. The object namespace is partitioned into several completely independent shards, each of which is designed to survive the usual failure modes (individual component failure, AZ loss, and single-AZ partition).
Each shard is backed by a postgres database using postgres-based replication from the master to both a synchronous slave and an asynchronous standby. Each database instance within the shard (master, sync slave, and async slave) is located in a different AZ, and we use Zookeeper for election of the master.
The shard requires only one peer to be available for read availability, and requires both master and synchronous slave for write availability. Individual failures (or partitions) of the master or synchronous slave can result in transient outages as the system elects a new leader.
The mechanics of this component are complex and interesting (as in, we learned a lot of lessons in building this). Look for a subsequent blog post from the team about the metadata tier.
Compute Jobs
Manta’s compute engine is built on top of the same metadata and storage tiers. Like the other supporting services, the services are effectively stateless and the real state lives in the metadata tier. It’s subject to the availability characteristics of the metadata tier, but it retries internal operations as needed to survive the transient outages described above.
If a given storage node becomes unavailable when there are tasks running on it, those tasks will be retried on a node storing another copy of the object. (That’s one source of the “retries” counter you see in “mjob get”.) Manta makes sure that the results of only one of these instances of the task are actually used.
The durability level of an object affects not only its availability for compute (for the same reasons as it affects availability over HTTP as described above), but also the amount of concurrency you can get on an object. That’s because Manta schedules compute tasks to operate on a random copy of an object. All things being equal, if you have two copies of an object instead of one, you can have twice as many tasks operating on the object concurrently (on twice as many physical systems).
Final notes
You’ll notice that I’ve mainly been talking about transient failures, either of software, hardware, or the network. The only non-transient failure in the system is loss of a ZFS storage pool; any other failure mode is recoverable by replacing the affected components. Objects with durability of at least two would be recoverable in the event of pool loss from the other copies, while objects with durability of one that were stored on that pool would be lost. (But remember: storage pool loss as a result of any normal hardware failure, even multiple failures, is unlikely.)
I also didn’t mention anything about replication in the storage tier. That’s because there is none. When you PUT a new object, we dynamically select the storage nodes that will store that object and then funnel the incoming data stream to both nodes synchronously (or more, if durability level is greater than 2). If we lose a ZFS storage pool, we would have to replicate objects to other pools, but that’s not something that’s triggered automatically in response to failure since it’s not appropriate for most failures.
Whether in the physical world or the cloud, infrastructure services have to be highly available. We’re very up front about how Manta works, the design tradeoffs we made, and how it’s designed to survive software failure, hardware component failure, physical server failure, AZ loss, and network partitions. With a three AZ model, if all three AZs became partitioned, the system chooses strong consistency over availability, which we believe provides a significantly more useful programming model than the alternatives.
For more detail on how we think about building distributed systems, see Mark Cavage’s ACM Queue article “There’s Just No Getting Around It: You’re Building a Distributed System."