on
Heatmap coloring
Brendan has written a great 5-part series on filesystem latency. Towards the end of part 5, he alluded to a lesser-known feature of Cloud Analytics heatmaps, which is the ability to tweak the way heatmaps are colored. In this post I’ll explain heatmap coloring more fully. Keep in mind that this is a pretty advanced topic. That’s not to say that it’s hard to understand, but rather it’s somewhat complicated and you rarely actually need to tweak this. But when you do, it can be very valuable.
A brief review of heatmaps
Since it’s hard to explain heatmaps with just text and a static picture, I’ve made a screencast explaining the basic idea while pointing out the relevant parts. To summarize, look at this heatmap of HTTP request latency for my test server:
![]()
On the x-axis we have time, which scrolls left if you’re looking at live data. On the y-axis we have latency, from 0 to 140ms. The heatmap is partitioned into buckets, each representing a particular latency range (e.g., 2ms) at a particular time on the x-axis. The darkness of each bucket represents the number of requests completed at that latency range at that second. In this example we can see that many requests took just a couple of milliseconds (from the band at the bottom), while most of the rest took between 50-60ms (the dark band in the middle), with some outliers above that (the more dispersed cloud at the top).
Coloring the heatmap
There are two dimensions of color in our heatmaps: we use hue (base color, e.g., orange vs. red vs. blue) to represent some other dimension of the data. For example, this heatmap is just like the one above, but I’ve used different hues to represent the URLs requested of my web server:
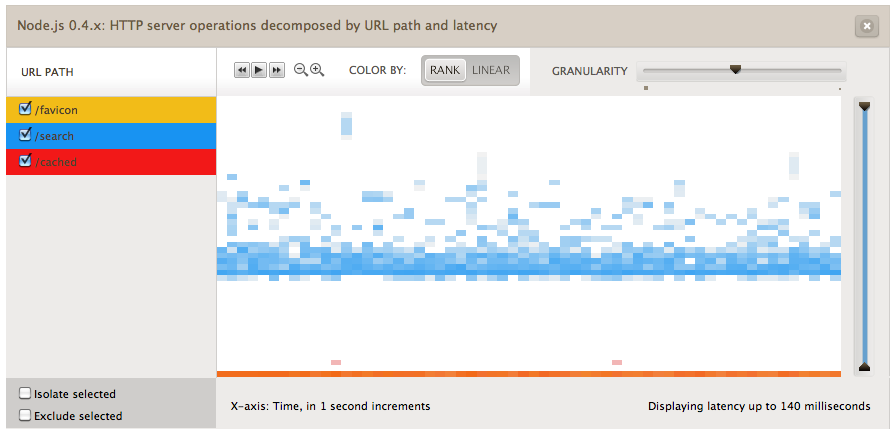
This is important for understanding patterns in the data (e.g., some particular URL might be slower than others). I’ve covered an example using garbage collection previously.
The other dimension is saturation, or darkness. As I mentioned above, we use saturation to convey quantity: the more requests completed in a certain latency bucket, the darker that bucket appears. But how much darker? That depends on how we choose to color the heatmap.
Rank-based vs. linear coloring
The most obvious way to color the heatmap (which is not what we do by default) is called linear coloring and it works like this:
- First, find the maximum-valued bucket in the heatmap. (That is, find the bucket with the largest number of requests.)
- For each bucket, assign the saturation on a scale from 0 to 1 by taking the value in that bucket and dividing by the value of the maximum-valued bucket.
- If a bucket has a non-zero value, no matter how small compared to the maximum-valued bucket, color it at least one shade darker than the background so it doesn’t get completely lost.
In other words, the darkness of each bucket is directly proportional to the value of the bucket (i.e. how many requests fell into that bucket). Here’s a heatmap using the same data as the one I showed above, but using linear coloring (and with several buckets labeled with their values for reference):
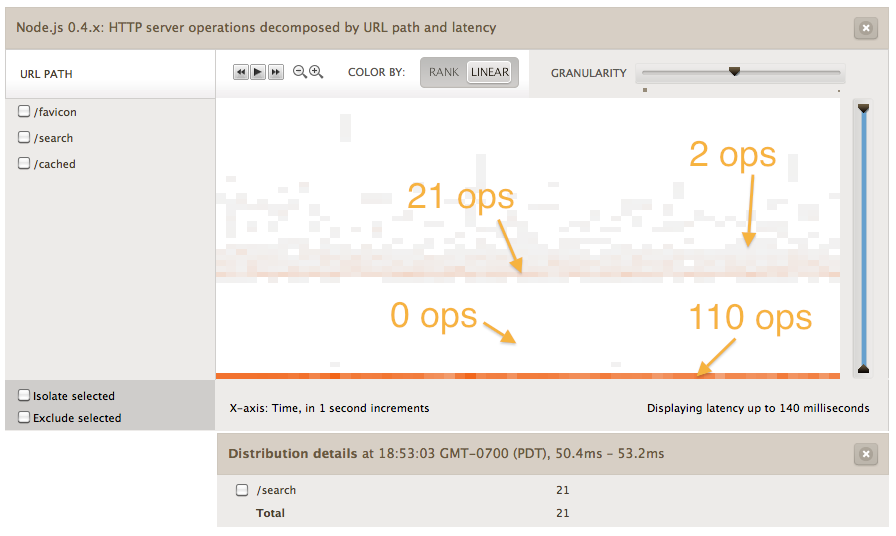
The problem with linear coloring is that it hides outliers that can be very significant. For example, imagine your web server is servicing 950 requests per second within 10ms and 50 requests per second at 1s. The 1s bucket would be colored about 50/950 = 5% as dark as the 10ms bucket. Most likely, the 50 slow requests would be barely visible at all. But 5% of requests being pathologically slow is very significant! Another example is what we saw in the example heatmaps above: the band around 0-2ms is very dense and dark, while the rest of the requests are represented with a more dispersed cloud. Each of the buckets in the cloud is much smaller, so the cloud is barely visible at all, but together the cloud itself is at least as large as the band at the bottom.
The other way we color a heatmap is what we call rank-based, which works as follows:
- Sort all the buckets with non-zero values by value, with the lowest-valued buckets first.
- For each bucket, assign the saturation on a scale from 0 to 1 by taking the position of the bucket in the sorted list and dividing by the length of the list.
Put differently, you assign the lightest saturation to the smallest bucket, the next lightest saturation to the next smallest bucket, and so on until you assign the darkest saturation to the largest-valued bucket.
Coloring methods in practice
In Cloud Analytics, you can toggle which of these coloring methods to use by clicking the “Color by” control:

Below are two heatmaps of the same data as above, one using the default rank-based coloring:
![]()
and the other using linear:
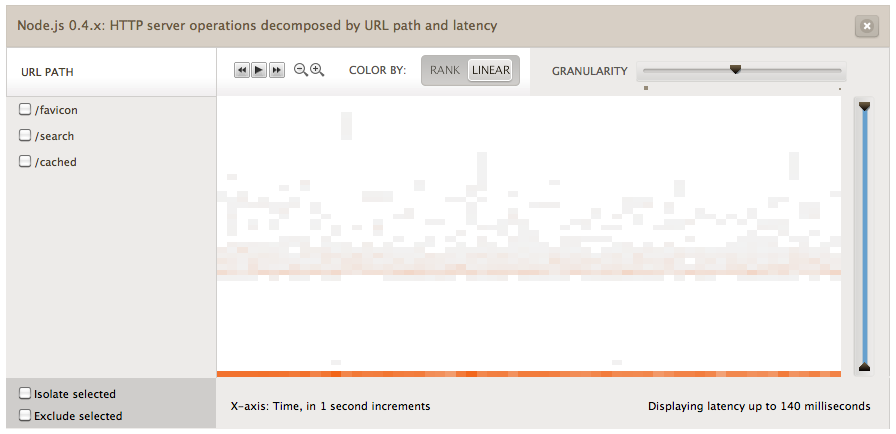
See the difference? We use rank-based coloring by default because it emphasizes patterns and highlights outliers, which we believe is usually more useful than seeing the proportion of requests being serviced quickly or slowly. The example above wasn’t as contrived as it sounds: it’s very common to have pathological workloads where literally 95% of operations are fine but the remaining ones are bringing the system to its knees. It’s important to be able to see those outliers quickly.
Conclusions
Since many distributions can’t be accurately summarized with a few numbers, a heatmap is a very useful tool for visualizing whole distributions. As with any such tool, choices have to be made about how to visually present the numeric data, and sometimes it’s useful to be able to see the data in different ways. Rank-based and linear coloring are two ways we present data through heatmaps. Both have their uses, but if you’re not sure what you want, we’ve found that the rank-based default is likely the right choice for understanding performance data.