on
Welcome to Cloud Analytics
We’ve been talking for several weeks now about our work on Cloud Analytics. Today, we’re showing the world what we’ve put together. Now available on Joyent’s Node.js Service: a first look at Cloud Analytics in action – on your very own Node.js application.
Cloud Analytics (CA for short) is a tool for real-time performance analysis of production systems and applications deployed in the cloud. If you’ve got a Node SmartMachine already, you can log into your account and start using CA right now. Note: most of the metrics require node version 0.4.0 or later. If you login and don’t see any data but you know your application is busy, make sure you’ve upgraded to the latest version of node.
First look
Suppose your node SmartMachine is running a web server. (Actually, don’t suppose it, you can go try it. It’s 5 lines of code.) When you log into the new portal you’ll see a world map showing HTTP operations by location, followed by a graph of HTTP operations over the last 30 seconds:
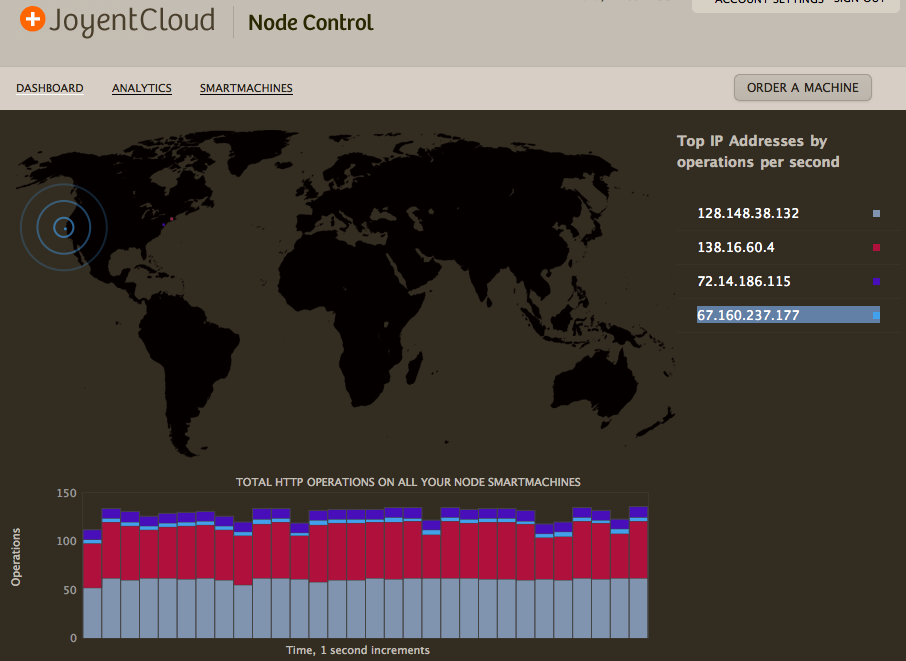
Here I’ve lit up a request from San Francisco by clicking on the IP address in the table on the right. This view gives you a quick overview of the HTTP traffic to your app and where it’s coming from. (We define an “HTTP operation” as a single request/response pair.)
To dive into what your application is actually doing, click the “Analytics” tab near the top of the screen. From here you can create an instrumentation, which is basically an instruction to the system to gather data for a particular metric. Here are the base metrics available on no.de today:
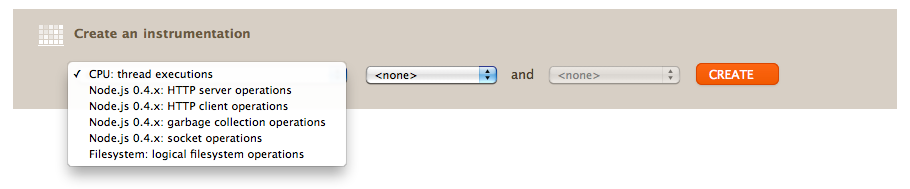
I’ll cover these in more detail below. For now, just pick HTTP server operations again. The next menu is populated with several options for decomposition. Choose “URL”, then click “Create” and wait a few seconds. If your app is servicing HTTP requests, you should see something like this:
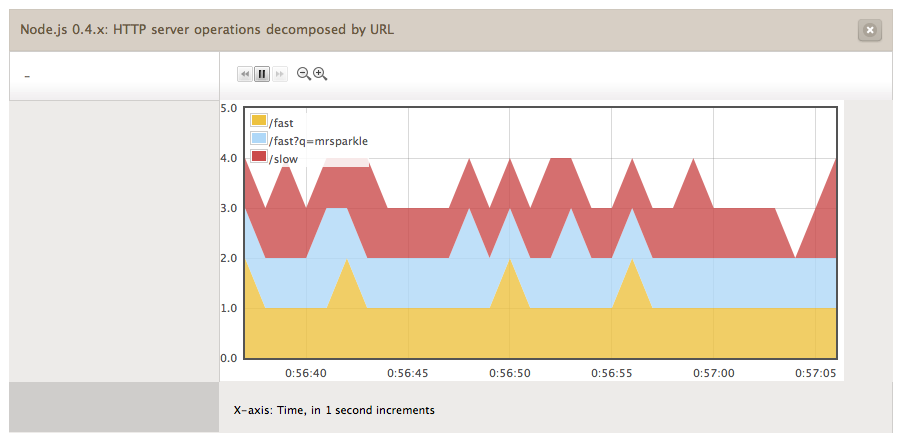
What just happened? You asked the system for more information about HTTP operations by URL. Behind the scenes, we used DTrace to instrument your application as it processes HTTP requests and responses. As the application processes each request/response pair, we’re collecting the URL. Shortly thereafter we aggregate that data and present it to you in real time.
Observing latency
As Brendan has explained, latency is the primary metric of performance for most applications. That’s because latency directly impacts users. If your site is servicing HTTP requests in 5ms, your users will have a snappy experience. If it’s taking 5000ms for each request, your users are in pain. Though we’re focusing on HTTP here, this idea extends way beyond HTTP: the performance perceived by whoever’s using a service, be they human or machine, is a direct result of the service’s latency in responding to the user, so that’s what you want to measure first to understand the server’s performance.
The tricky part about latency is that there’s so much data and it’s hard to summarize. You can measure the latency of each request, but how do you make sense of these numbers when your application is servicing tens, hundreds, or thousands of requests per second? A common technique is to plot the average over time, sometimes with marks for the standard deviation, but that by definition excludes the outliers – which can be very significant. And this method completely ignores the distribution of latency across requests: if half of the users are seeing great performance because their data is cached while others are seeing very high latency because their requests require fetching data from a poorly performing network database, by looking at the average you’ll think your service is performing “alright”. In fact, nobody’s actually seeing that average service time, and there’s no way for you to see that half of your requests are actually taking far too long!
With CA, we present latency as a heatmap, a tool you might remember from such visualizations as population density maps and precipitation level maps. Our heatmaps are not geographic, though. We use the x-axis for time, the y-axis for the latency of each request, and the saturation (darkness) of each pixel (actually, each bucket of pixels) denotes the number of requests in that latency range at that time. You can observe HTTP operation latency (which we define as the time between when the server receives the request headers and the time it finishes sending the response) by selecting “latency” from the second menu and hitting “Create” again. After we’ve collected data for a few seconds, this will look something like this:

Note that all of these requests are taking less than about 200us, but there’s a tight band around 100us and a more dispersed cloud above that. We can see if there’s a correlation between latency and URL by clicking one of the URLs on the left to highlight it:
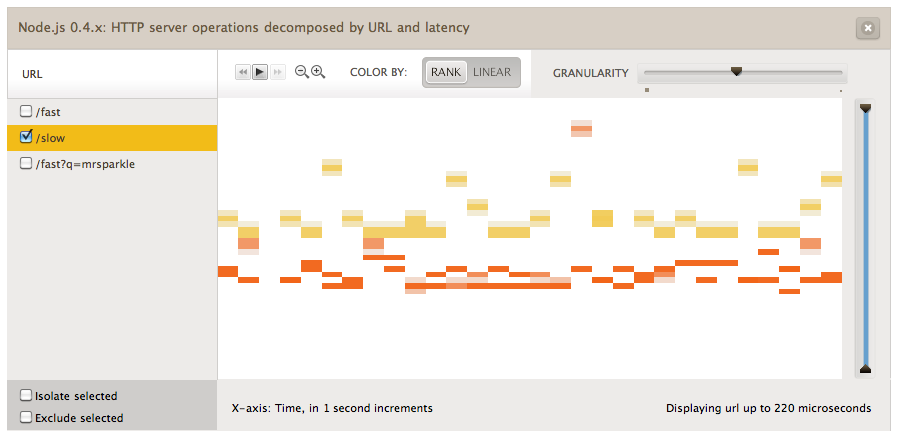
Indeed, requests for the “/slow” URL are taking longer than the others. The next step would be to find out why, but at this point I want to put this contrived example to rest and discuss the other metrics.
The metrics
Recall that we started with HTTP server operations because this application is a web server, and we focused on latency because that’s the primary metric of performance for a user-facing web service. But if you’ve already established that performance is bad right now, the next thing you want to know is where the latency is coming from. To answer that, we’ve provided a number of metrics for examining common sources of latency in web services:
- Node.js 0.4.x: HTTP server operations decomposed by method, URL, remote IP, remote port, and latency. As we’ve said, this is the primary performance metric for a web server. The decompositions allow you to look for correlations between latency and the various parameters of the HTTP request. The one that might need a little explaining is remote TCP port, which allows you to pick out multiple requests from the same client over the same TCP connection (using HTTP Keep-Alive).
- Node.js 0.4.x: HTTP client operations decomposed by method, URL, server address, server port, and latency. This metric examines HTTP requests and responses where the requests come from your node app rather than being served by it. This helps you identify when your server’s latency results from the latency of some other web service you’re using. For example, if your service stores data on Amazon’s S3, you can see how long those requests to the S3 web service are taking. If you find that another web service is the source of your high latency, then you can go investigate that other web service (if you’re able to) or rethink how your application uses it (perhaps by caching results where possible).
- Node.js 0.4.x: garbage collection operations decomposed by GC type and latency. This metric allows you to observe latency bubbles resulting from the Javascript virtual machine’s garbage collector. Recall that GC tracks allocated memory and frees unused objects so that programmers can (mostly) avoid worrying about memory allocation, but while the garbage collector is running, all of the application’s code is suspended. You can use this metric to observe GC in your node app. “Latency” here refers to how long the garbage collection operation took. If you see GC activity correlate with HTTP request latency spikes, you may need to rethink how memory is being used in your application to avoid creating so much garbage, or else tune the GC to avoid large spikes. We’ve used this metric to observe how mark-and-sweep takes longer than scavenge:
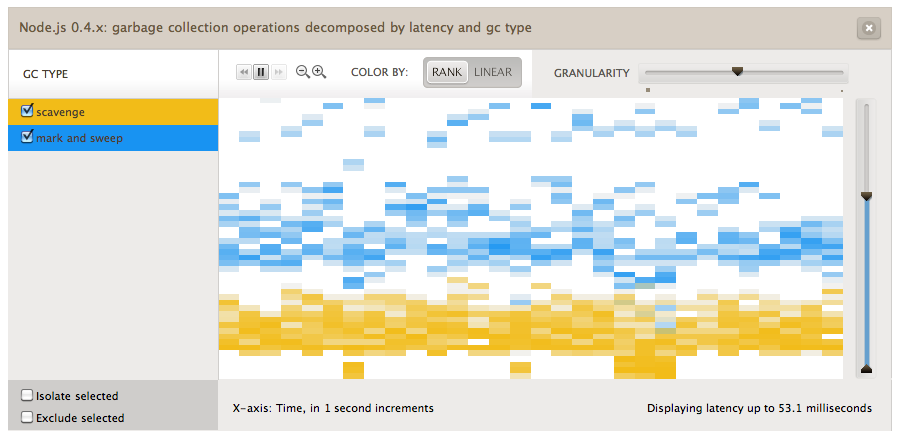
For more details, Bryan has a cool example of using this metric on an early prototype of CA.
- Node.js 0.4.x: socket operations decomposed by type, remote host and port, size, and buffered data. Socket operations are the basis of HTTP activity, WebSockets, and most other types of network activity as well. This metric provides observability for non-web applications, though we can’t show you latency directly at this level because it’s impossible to know which messages correspond with which others to form semantically relevant operations. The “size” and “buffered data” decompositions are unusual in that they generate heatmaps, but not based on latency. The y-axis instead represents bytes, and darker colored buckets denote more operations having a “size” or “buffered data” in the corresponding byte range. “Buffered data” refers to how much data is buffered inside node because the application has written more than the kernel can consume without blocking. If the application doesn’t pay attention to this, it can run out of memory. For more details, see the node documentation. Here’s an example illustrating this problem:

This uses the socket.io example chat program. This program dumped 30+ MB of data into the chat at once, which was larger than the client could immediately receive. It thus filled the kernel buffer and started buffering in userland. Subsequently the program continues to write smaller amounts (which is why we’re seeing more write operations) but the client is consuming data faster than the program is writing more data, which is why the “buffered data” is decreasing. Bryan posted a similar example with three clients a few weeks ago using an earlier prototype.
- Filesystem: logical filesystem operations decomposed by pid, application name, zone name (SmartMachine name), operation type, filesystem type, and latency. Disk I/O can always be a source of significant latency, so this metric examines one of the primary causes of disk I/O by applications: accessing the filesystem. If you see significant latency here corresponding with HTTP request latency, you could consider changing the way your application interacts with the filesystem (perhaps by prefetching or caching data). The decompositions help you identify precisely who is doing what so you can be sure you’re optimizing the right thing. Unlike the Node.js metrics, this metric examines all filesystem activity in your SmartMachine, not just that caused by node, so we provide decompositions by pid and application name.
- CPU: thread executions decomposed by pid, application name, zone name, runtime, and reason leaving CPU. This metric provides insight into applications’ use of the CPU. A “thread execution” is simply when a thread runs continuously on a CPU for a period of time. The execution starts when the thread is put on CPU and ends when the thread is taken off CPU for any reason. The number of executions by itself isn’t usually interesting, but the heatmap of runtime (how long the thread was on CPU) can be revealing because it shows you when your application has been running for long periods on CPU (i.e., is doing a lot of computation). If your application isn’t running for very long, you can look at why it’s coming off CPU. It might be blocking on a kernel lock (potentially indicating kernel lock contention), a userland lock (indicating user-level lock contention), a condition variable (indicating it’s probably waiting for some other event, like disk I/O or networking), etc. Or it might be runnable, in which case, it’s been booted off because something else of higher priority needed to run. This is the lowest-level and most subtle of the metrics we’ve provided, but we believe it will be valuable for shedding light on whether an application is actually on CPU most of the time (i.e., and that’s why it’s taking so long to serve requests). You might wonder why we didn’t just provide CPU utilization. The problem is that this number can be very misleading on multi-processor systems. With 16 cores your app may only be using 6% of the overall CPU but it’s still compute-bound because it’s got one core completely pegged.
In providing these particular metrics we’re seeking to give node developers the primary metrics they need to see how their application is performing overall as well as metrics to observe the common causes of latency in network applications: waiting for CPU, waiting for disk I/O, or waiting for network services. We don’t want to give users just numbers and graphs, but actionable data that will drive them to ask the next question, and the next, until the bottleneck has been identified. Remember, though, that the appropriate response depends entirely on the situation. The suggestions above are just examples. In general, CA may not always get you straight to root cause, but it will help you quickly zero in on problem components (and, importantly, quickly verify where the problem is not).
Behind the scenes
Earlier I alluded to the fact that creating an instrumentation causes the system to dynamically instrument itself and collect the resulting data. All of the above metrics use DTrace under the hood. Robert has written separately about the underlying DTrace probes that make all this possible, which landed in node 0.4.0 (thanks Ryan!). That’s why you’ll only see data for the Node.js metrics if your application is using node 0.4.0 or later.
We’re also using Bryan’s new llquantize() aggregating action for DTrace to keep the data overhead low while maintaining high resolution where it matters.
Because we’re using DTrace, the performance overhead when these metrics are not active is near zero, and it’s minimal even when the metrics are enabled. More importantly, you can use CA safely on production systems so you can examine real performance problems, not just approximations recreated in a test environment.
Looking ahead
The golden rule of performance optimization is to measure first and then optimize, because the overall time saved by speeding up one subtask is limited by how much of the overall time that subtask consumed in the first place. With CA, you can measure performance directly and see the effect of software or configuration changes immediately on production systems. Our work on CA is informed by using it internally to examine real performance problems of customers in the Joyent Public Cloud.
While the CA we’ve rolled out today will already enable users to analyze real performance problems, we’re far from done. Over the coming weeks, we’ll be working on new metrics for different types of cloud applications (in the node world and beyond) and new features for CA itself. The other important side of this problem is observability for cloud operators, who need much of the same kinds of information for the systems running their clouds and additional metrics to monitor overall resource utilization. Stay tuned for more on CA for cloud operators.
Finally, to read more about using heatmaps to analyze complex real-world problems check out Brendan’s article in CACM on Visualizing System Latency.
Thanks a lot to the rest of the Cloud Analytics team, the portal team, and everyone at Joyent for the hard work in recent weeks to make this no.de release possible. And if you’ve got a node SmartMachine, go try out CA!