on
Event ports and performance
So lots of people have been talking about event ports. They were designed to solve the problem with poll(2) and lots of file descriptors. The goal is to scale with the number of actual events of interest rather than the number of file descriptors one is listening on, since the former is often much less than the latter.
To make this a little more concrete, consider your giant new server which maintains a thousand connections, only about a hundred of which are active at any given time. It has its array with a thousand socket file descriptors, and sits there in a loop calling poll to figure out which of them can be read without blocking. poll waits until at least one of them is ready, returns, and then the program iterates over the whole array to see which descriptor(s) poll said was ready. Finally, it processes them one by one. You waste all this time iterating over the array, not to mention the time copying it between the kernel and userland every time you call poll.
It’s true that you could multi-thread this and save some time, but the overhead of thousands of threads (one for each fd) adds up as well.
This is the problem event ports are designed to solve. Interestingly enough, this was not the first attempt to speed up this scenario. /dev/poll was introduced in Solaris 7 for the same purpose, and works great - except that multi-threaded apps can’t use it without [lots of slow] synchronization. Linux has epoll and BSD has kqueue, about neither of which do I pretend to know much.
Event ports, as applied to file descriptors, are basically a way of telling the OS that you’re interested in certain events on certain descriptors, and to deliver (synchronous) notification of said events on said descriptors to a particular object (…which also happens to be a file descriptor). Then you can have one or more worker threads sleeping, waiting for the OS to wake them up and hand them an event, saying “here you go, this socket’s got something to read.” You can actually have lots of worker threads hanging around the same event port and let the OS do your “synchronization” - they probably don’t need to communicate or share any common state (depending on your app, of course).
No expensive copies. No traversing huge arrays finding needles in haystacks.
At least, in theory. Until now, nobody’s really measured their performance with any microbenchmarks. My recent addition of event ports of libevent gave me an excuse to run libevent’s own bunchmarks and see how it performed. The benchmark basically just schedules lots of read/write events, and has a few parameters: the number of file descriptors, the number of writes, and the number of active connections (the higher this number, the more the benchmark spreads its writes over the many file descriptors).
Results
All benchmarks below were run on a uniprocessor x86 machine with 1G memory. Note the vertical axes - some of the graphs use logarithmic scales. And remember, these are the results of the libevent benchmark, so differences in performance can be a result of the underlying polling mechanism as well as the libevent implementation (though since the implementations don’t matter, it’s assumed that most affects are attributable to the underlying polling mechanism)
Let’s start with the simplest example. Consider small numbers of file descriptors, and various methods of polling them:
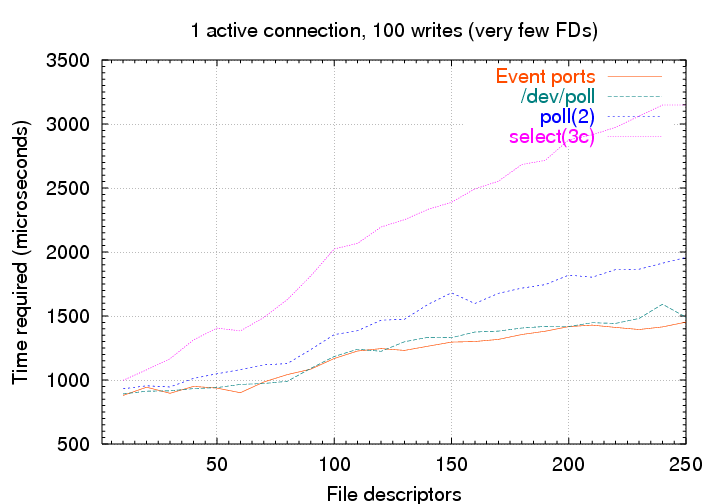
On this machine, event ports are fast, even for small numbers of file descriptors. In some circumstances, event ports are slightly more expensive for small numbers of file descriptors, particularly when many of them are active. This results because (a) when most of your descriptors are active, then the work done by poll is not such a waste (because you have to do it anyway), and (b) event ports require two system calls per descriptor event rather than one.
But let’s look at much larger numbers of file descriptors, where event ports really show their stuff. Note that /dev/poll has a maximum of about 250 fd’s (Update 7/12/06: Alan Bateman points out that you can use setrlimit to update RLIMIT_NOFILE to increase this to much higher values), and select(3c) can only handle up to about 500, so they’re omitted from the rest of these graphs. This graph has a logarithmic scale.
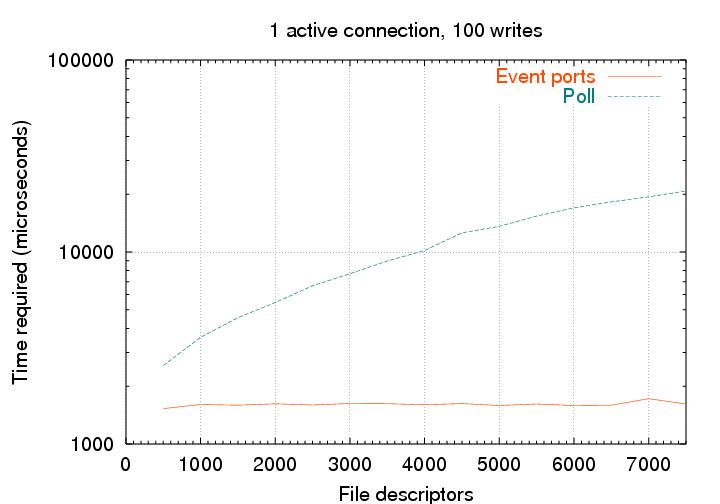
Wow. That’s about a 10x difference for 7,500 fd’s. ‘Nuff said. Finally, let’s examine what happens when the connections become more active (more of the descriptors are written to):
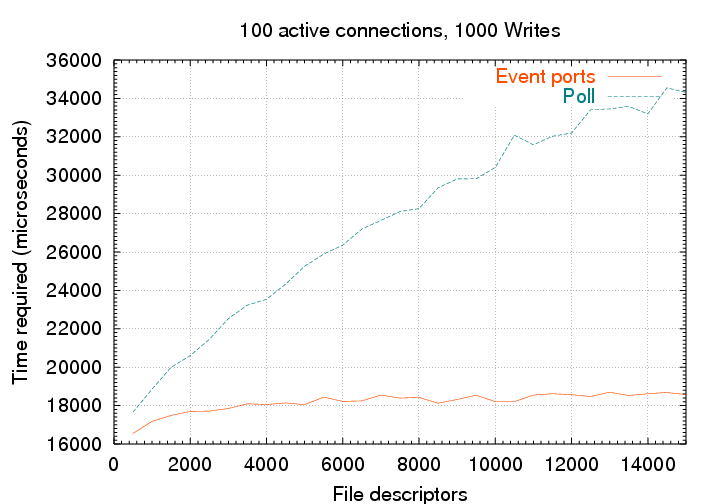
Event ports still win, but not by nearly as much (about 2x, for up to 15,000 fd’s). Less of poll’s array traversing is unnecessary, so the difference is smaller. But in the long run, event ports scale pretty much at a constant rate, while poll scales linearly. Select is even worse, since it’s implemented on top of poll (on Solaris). /dev/poll is good, but has the problem mentioned earlier of being difficult to use in a multi-threaded application.
For large numbers of descriptors, event ports are the clear winner.
Benchmarking can be difficult, and it’s easy to miss subtle effects. I invite your comments, especially if you think there’s something I’ve overlooked.